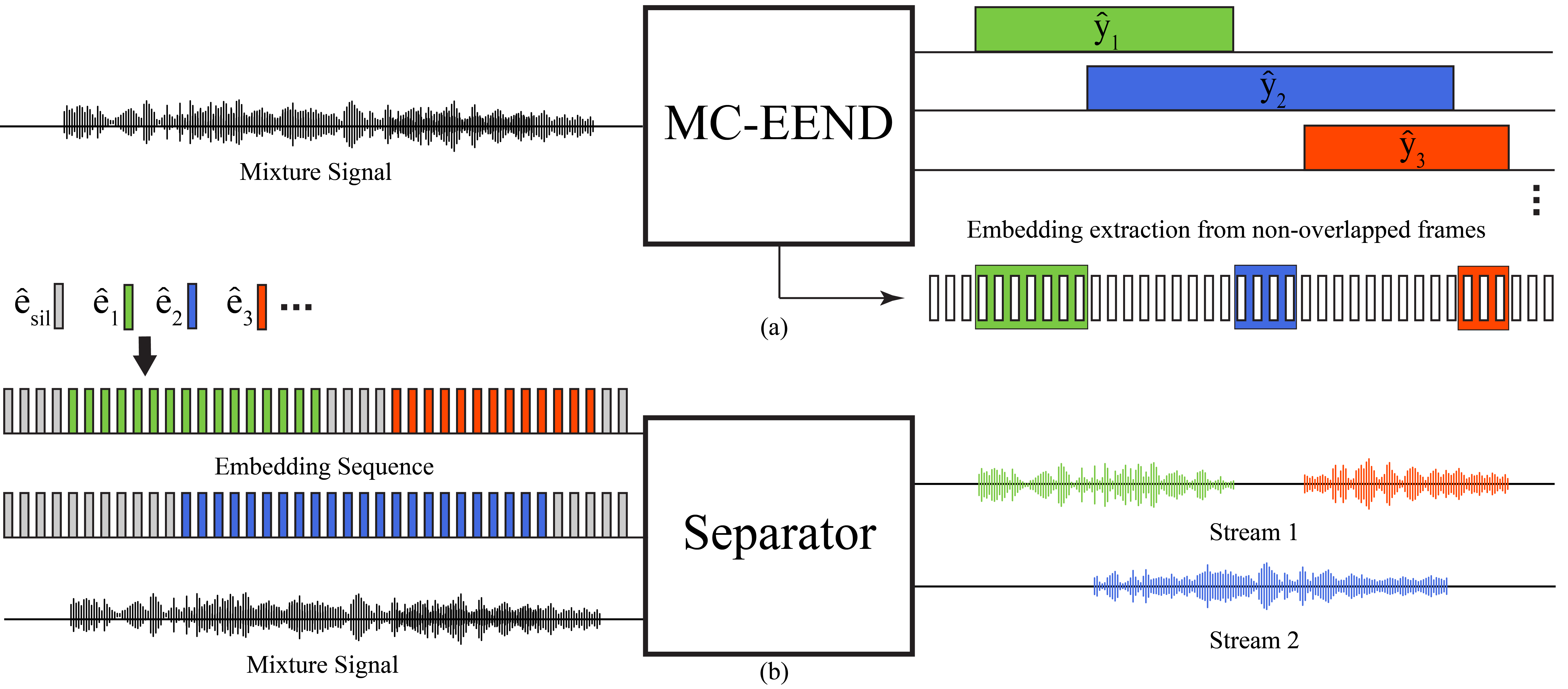
We introduce a new framework, termed "speaker separation via neural diarization" (SSND), for multi-channel conversational speaker separation. This approach employs a deep neural network (DNN) for speaker diarization to demarcate the speech activities of individual speakers. Leveraging the estimated utterance boundaries from neural diarization, we generate a sequence of speaker embeddings. These embeddings, in turn, facilitate the assignment of speakers to two output streams of the separation model. The SSND approach tackles the permutation ambiguity issue of talker-independent separation during the diarization phase, rather than during separation. This distinction permits non-overlapped speakers to be assigned to the same output stream, enabling the processing long recordings missing from standard CSS. Another advantage of SSND lies in the inherent integration of speaker separation and diarization, enabling sequential grouping of the discontinuous utterances of the same talker. Our SSND framework achieves state-of-the-art diarization and ASR results, surpassing all existing methods on the open LibriCSS dataset.
Example 1
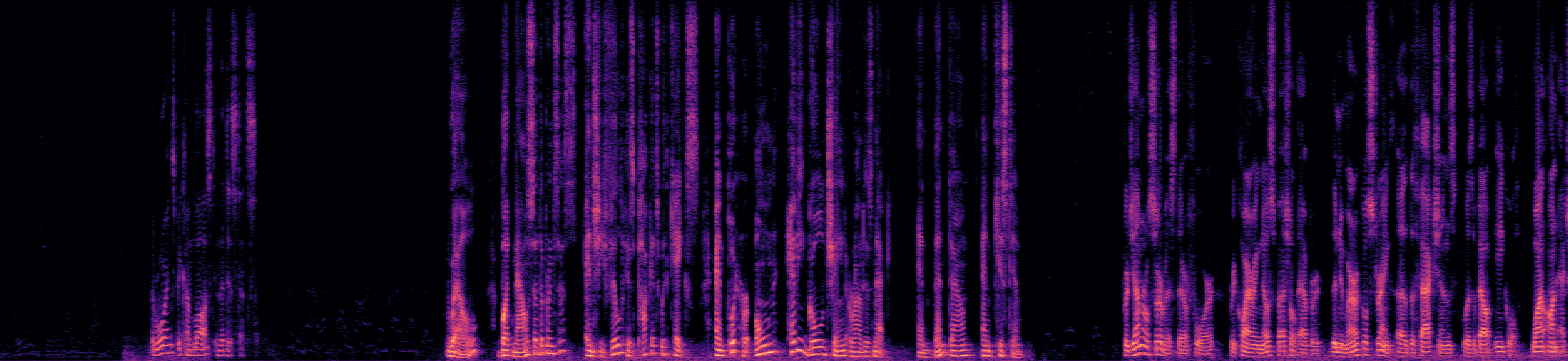
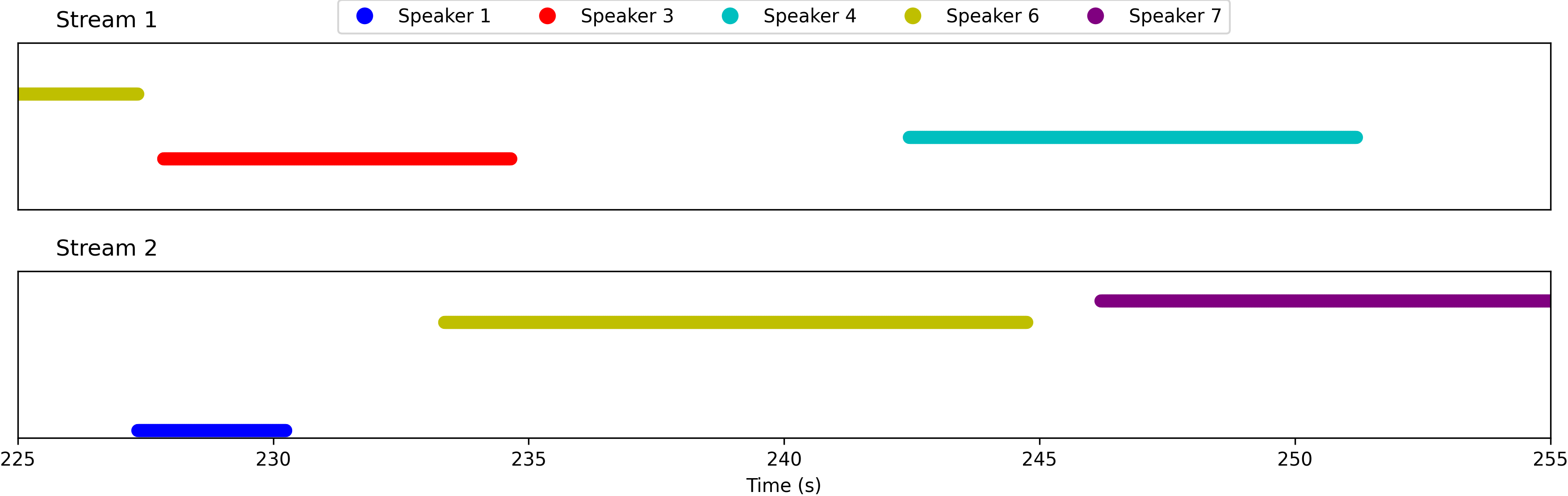
This segment is from the "overlap_ratio_40.0_sil0.1_1.0_session1_actual39.7" recording of the LibriCSS dataset, spanning from 225s to 255s, with 40% overlap ratio.
Reverberant Mixed Audio
Separated Audio Stream 1
Separated Audio Stream 2
Embedding Sequence Indices based on Diarization Estimates
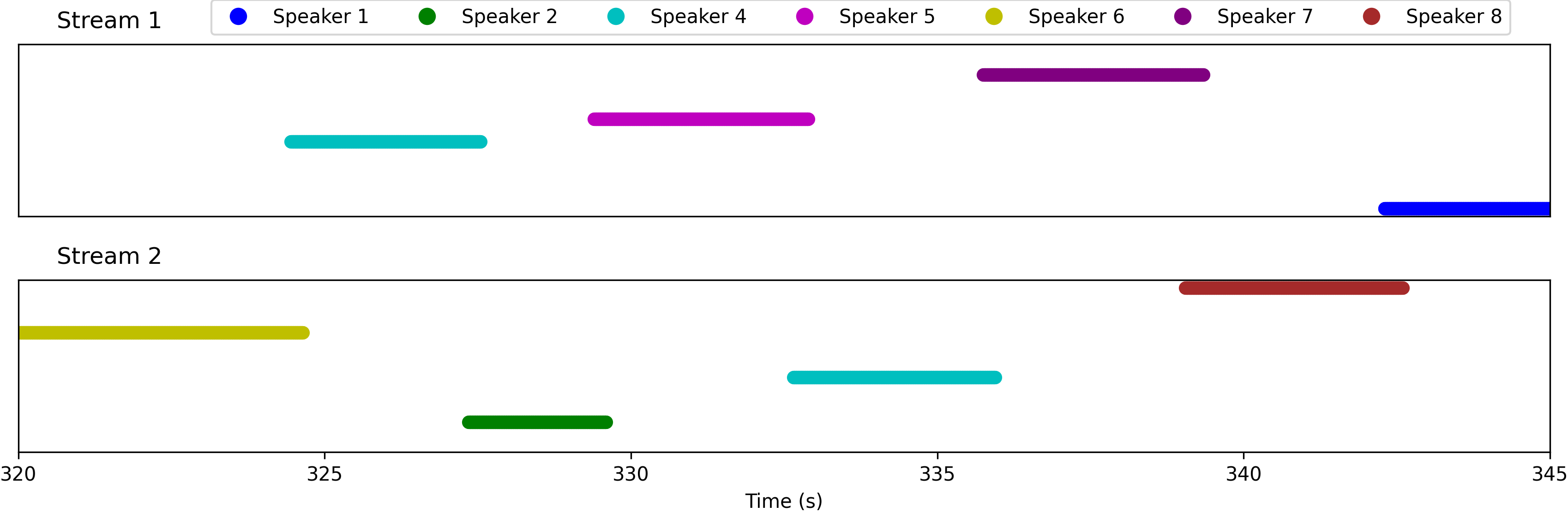
Example 2
This segment is from the "overlap_ratio_0.0_sil0.1_0.5_session4_actual0.0" recording of the LibriCSS dataset, spanning from 320s to 345s, which encompasses speech from seven unique speakers with no speech overlap. Note that the estimated speakers boundaries extend slightly beyond the actual limits of their speech.
Reverberant Mixed Audio
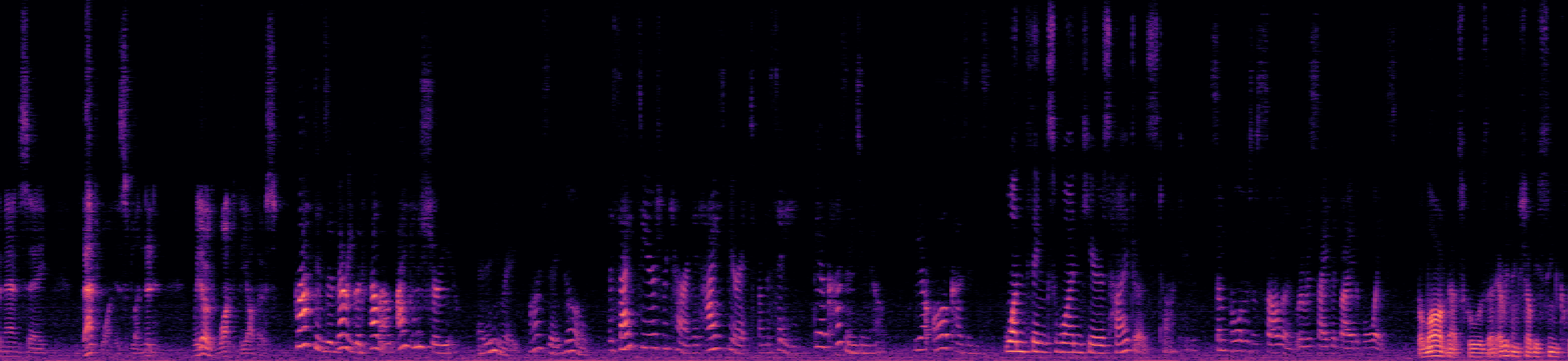
Separated Audio Stream 1
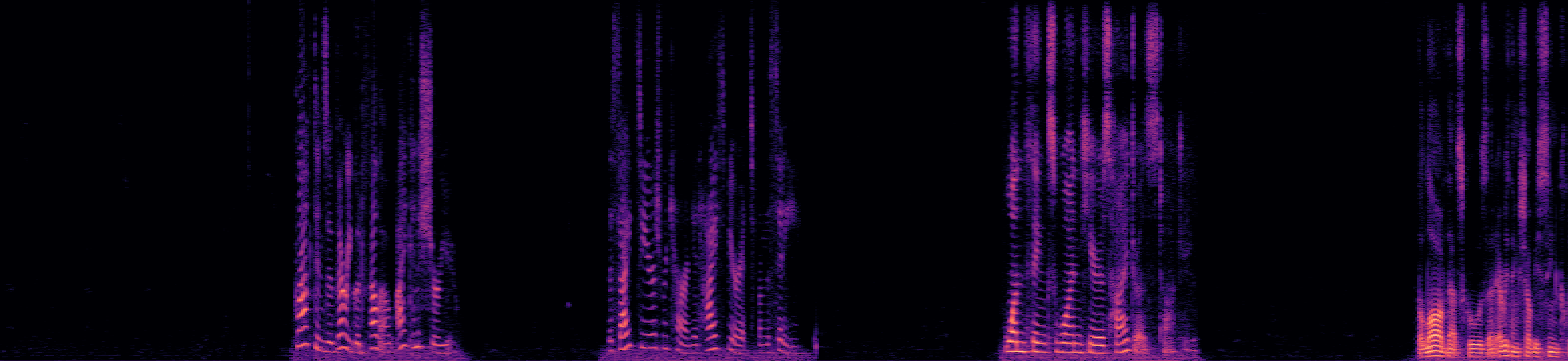
Separated Audio Stream 2

Embedding Sequence Indices based on Diarization Estimates
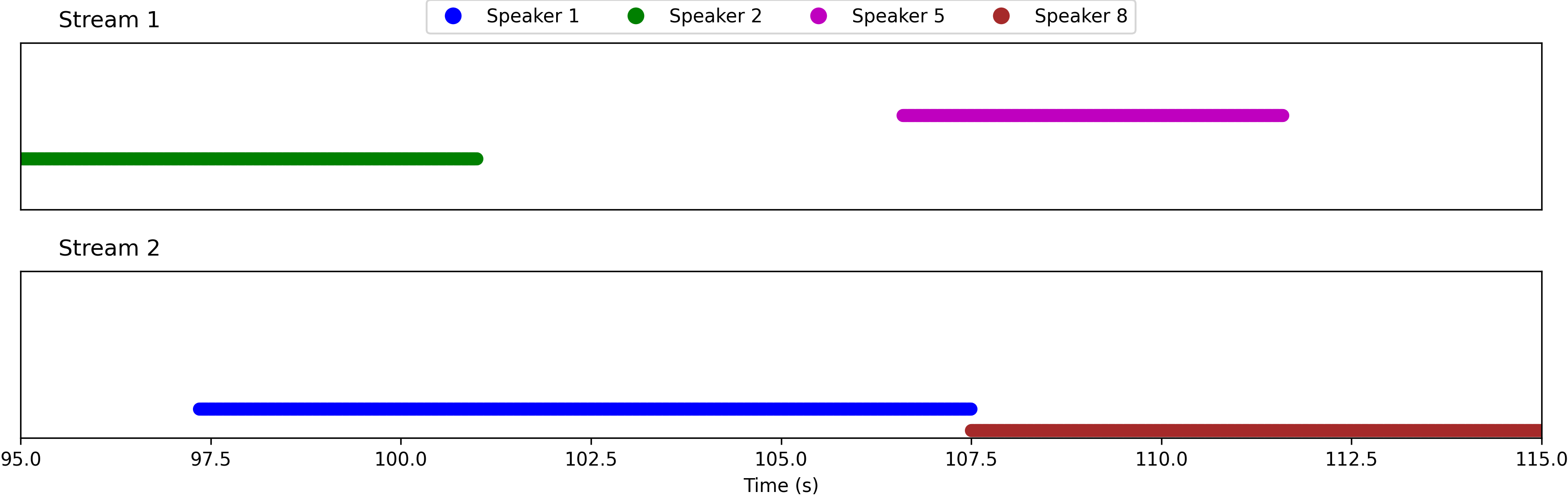
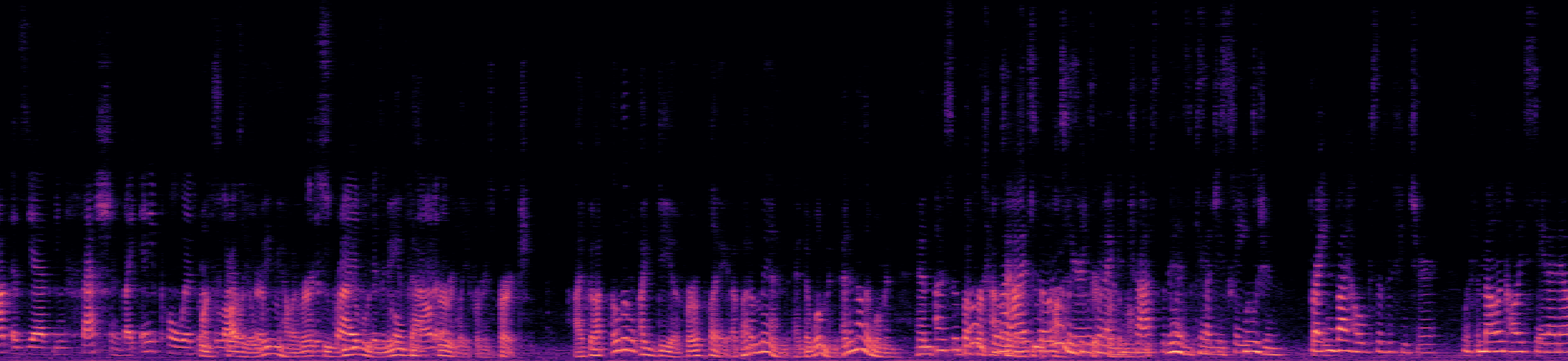
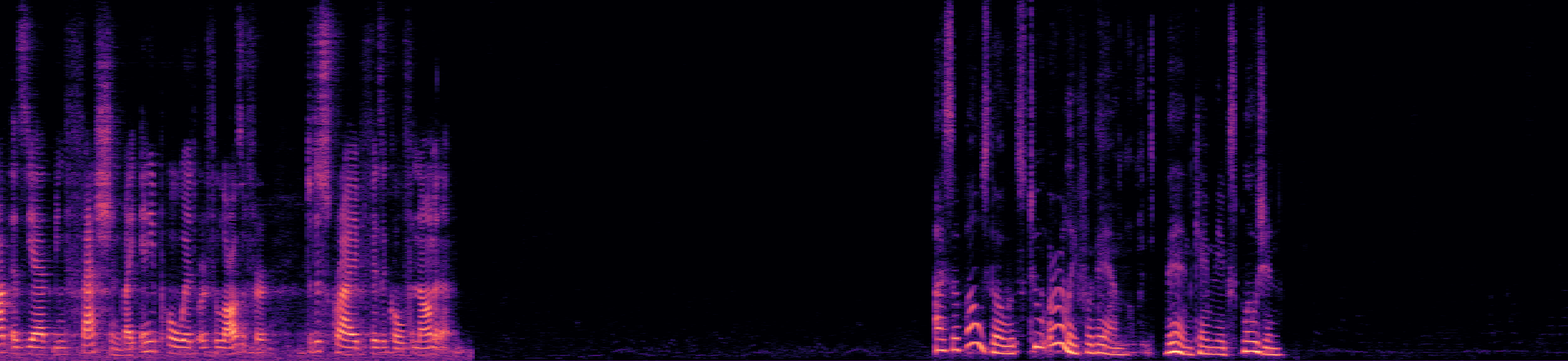
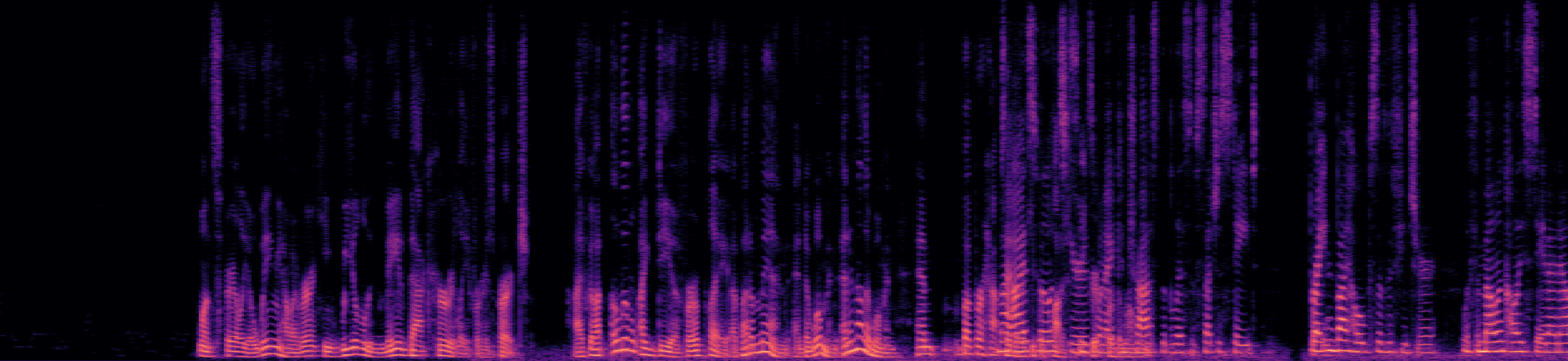
Example 3
This example, taken from the "overlap_ratio_40.0_sil0.1_1.0_session9_actual39.9" recording of the LibriCSS dataset (from 95s to 115s), presents a challenging scenario with 3-fold speech overlap. Although the SSND model is trained with examples containing only two-speaker overlap, it isolates one speaker in one stream while maintaining the remaining speakers in the other stream. Listen and observe the results below.
Reverberant Mixed Audio
Separated Audio Stream 1
Separated Audio Stream 2
Embedding Sequence Indices based on Diarization Estimates